存储过程是什么:
存储过程就是一组SQL语句
存储过程的语法
delimiter $$
create procedure <存储过程名称>([参数1,参数2,…])
begin
<SQL 语句1>;
<SQL 语句2>;
…
end$$
delimiter;
begin 和end之间的SQL语句就是存储过程的内容,被称为过程体,过程体里可有多条完整的SQL语句,但是每条SQL语句都要以;结尾
delimiter用于定义结束符。通常,SQL语句的默认结束符为“;”,但为了将过程体内部的语句分隔符与SQL本身执行层面的结束符区别开,要先用delimiter关键字暂时将SQL语句的默认结束符改为其他符号,一般改成“。所以后跟了”,表示定义存储过程的语句到此结束。
参数模式有3种,分别如下。
• in:输入的参数。
• out:作为返回值的参数(输出的参数)。
• inout:既可以作为输入参数,也可以作为返回值的参数。
存储过程定义好后,使用call关键字就可以实现调用。
存储过程有如下优点。(1)简化查询语句。将重复性查询语句封装成存储过程,在需要用到的地方直接调用定义好的存储过程,这大大简化了SQL语句,使查询语句更加灵活、易读。(2)提高运行效率。运行查询语句时,数据库是先编译后运行的。而存储过程是一个已经编译好的代码块,直接调用存储过程,其运行效率比普通查询语句高。(3)加强数据安全。通过存储过程能够使没有权限的用户在控制之下,间接地提取数据库中的数据,从而确保数据的安全。(4)易于维护。假设你要开发一个使用数据库的应用程序,你应该将SQL语句写在哪里呢?如果你将SQL语句内嵌在应用程序代码中,那么将使整个程序变得混乱且难以维护。通常情况下,我们应该将SQL语句和应用程序代码分开,将SQL语句存储在所属数据库的存储过程中,并且只在应用程序代码中调用存储过程。这样,数据库专业人员可以随时对存储过程进行修改,而不对应用程序源代码产生影响,更加易于维护。(5)减少网络流量。由于存储过程是一个编译好的代码块,当在其他计算机上调用该存储过程时,网络中传送的将是编译好的代码块,这可以大大减少网络流量并降低网络负载。
缺点。(1)可移植性差。存储过程是存储在特定数据库中的,若将程序移植、关联到其他不同的数据库中,可能会导致存储过程失效或运行出错。(2)调试困难。SQL语句的开发环境不如其他编程语言的开发环境功能全面,存储过程的调试要比一般程序的调试困难。(3)无法处理复杂的业务逻辑。SQL语言有它本身的局限性,因为SQL语言是一种结构化查询语言,只擅长查询数据。对于复杂的业务逻辑,存储过程实现起来比较困难且难以维护
创建表的语法:
create table 表名称(
列名1 数据类型,
列名2 数据类型
);
插入数据的语法规则
insert into table(列名1,列名2,列名3,) values(值1,,..值3);
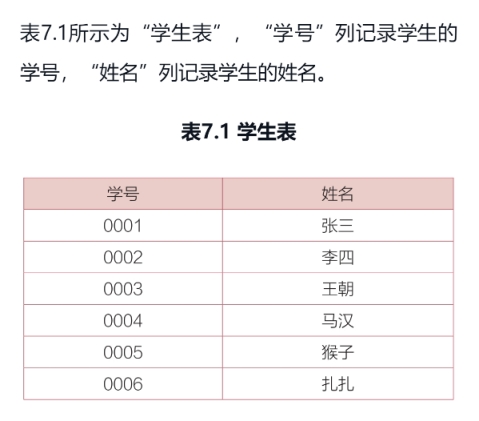
1) 不带参数的存储过程。定义一个查询所有学生姓名的存储过程并调用
delimiter $$
create procedure student_name()
begin
select 姓名
from 学生表
end$$
delimiter;
调用:
call student_name();
2) 带in参数模式的存储过程。定义一个存储过程查询指定学号的学生姓名
delimiter $$
create procedure get_name(in num varchar(100))
begin
select 姓名
from 学生表
where 学号=num;
end$$
delimiter;
call get_name(‘0001’);
3) 带out参数模式的存储过程。
定义一个存储过程查询指定学号的学生姓名,并将获取的学生姓名赋值给变量并输出。
delimiter $$
create procedure get_name1(in num varchar(100),out st_name varchar(100))
begin
*select 姓名 into st_name*
from 学生表
where 学号=num;
end$$
delimiter;
将查询到的姓名通过into关键字赋值给了变量st_name,在get_name1后面的括号中将变量st_name通过out关键字设置为输出参数。这样,过程体中的查询结果不会直接输出,而是赋值给了变量st_name,作为返回值。
call get_name1(‘0001’,@name);
4) 带inout参数模式的存储过程。
delimiter $$
create procedure get_mull(inout a int)
begin
set a = a*2;
end$$
delimiter;
set @num = 10;
call get_mull(@num);
select @num;
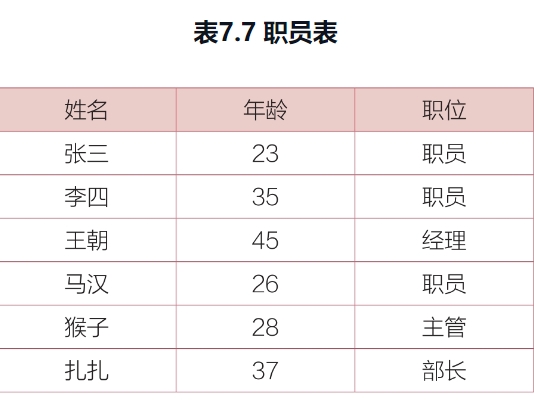
写出SQL的存储过程,
建立一个“职员表”,列名是“姓名”“年龄”和“职位”,
然后向里面插入6条数据,
查询出年龄大于30岁的职员的所有信息。6条数据如表7.7所示。
create table 职员表(
姓名 varchar(20),
年龄 int,
职位 varchar(20)
);
delimiter $$
create procedure get_meg(in num int)
begin
select *
from 职员表
where 年龄>num;
end$$
delimiter;
insert into table 职员表(姓名,年龄,职位) values(‘张三’,23,’职员’);
变量,顾名思义,就是能变化的量。它不是一个特定的值,但是我们可以通过给变量赋值,让它变为确定的值。
数据库中的变量有两种:系统变量和用户自定义变量
系统变量时用于设置数据库行为和方式的参数:(一般设有默认值)
启动数据库占用多大的内存,设置访问权限,日志文件的大小,文件存放位置
用户自定义变量:包括会话变量和局部变量
赋值符号“=”和“:=”有什么区别呢?
因为在MySQL数据库中没有“==”这一比较符号,使用select关键字时,进行等于比较使用的是“=”符号,为了系统可以区分这是赋值还是比较,特意增加了一个变量的赋值符号“:=”。也就是说,使用select关键字赋值,必须使用“:=”,以区分比较符号“=”。
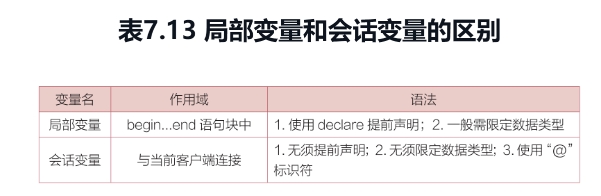
会话变量和局部变量的区别:
(1) 会话变量时在当前会话中起作用的变量,其作用域和声明周期均与当前客户端连接相同;会话变量主要用于在不同SQL语句之间传递数据
会话变量的声明和赋值是同时进行的。
*使用set关键字声明并赋值*
*set @会话变量名=值或表达式;*
使用select关键字声明并赋值
select @会话变量名 := 值或者表达式;
select 值或者表达式 into @会话变量名;
select 字段 into @会话变量名 from …;

(2) 局部变量
*局部变量被放在begin和end之间的语句块中*,其作用域仅限于该语句块内,也就是超过该作用域就不能使用这个局部变量了。
局部变量语法
*declare var_name, type [default value];*
• declare是声明局部变量的关键字。
• var_name是变量的名称,可以同时声明多个变量。
• type是变量的数据类型。
• default value将变量的默认值(初始值)设置为value。若无default,则变量的默认值
为null。
声明局部变量后,还*可以对局部变量重新赋值**,set 局部变量名 = 值或者表达式;*
declare c,d int default 0;
set c = a + b;

面试题:
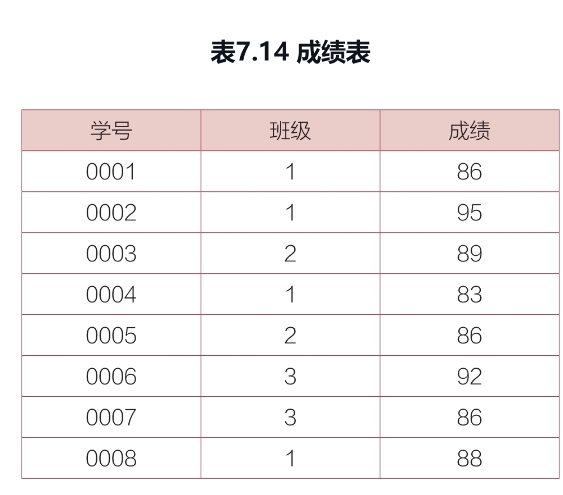
表7.14所示为“成绩表”,包括“学号”“班级”和“成绩”3列,使用变量计算每个班级的成绩,并进行排名,若成绩一样,则并列排名。
set @rank = 0 ,@class = null, @score = null;
select *, (
case
when @class = 班级 then (case when @score = 成绩 then @rank
else @rank := @rank + 1 end)
else @rank := 1 end
) as 排名
@class := 班级
@score := 成绩
from 成绩表
order by 班级asc,成绩 desc;
更改表中的数据使用关键字update
语法格式:
update 表名称 set 列名称 = 新的值;
在表中添加列的书写方法:
alter table 表名称 add column 列名 数据类型;
将某种数据类型的表达式显示的转换为另一种数据类型cast()函数
用法 cast(字段名 as 转换的类型);
从某日期减去指定的时间间隔后的日期date_sub(date,interval expr type);
select date_sub(‘2018-03-09’,interval 11 hour) as newdate;
计算两个时间的差值:timestampdiff()

函数:
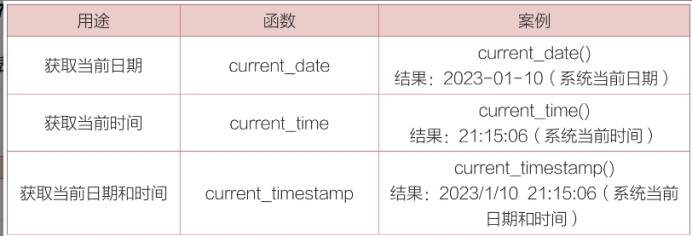
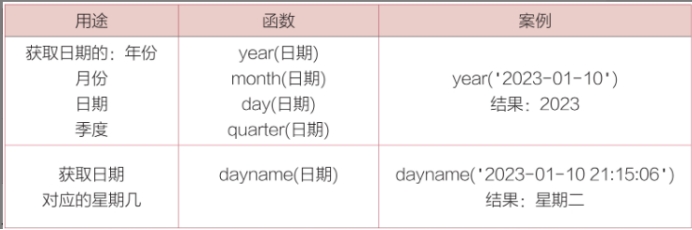
将现有格式转换成想要的日期格式,MySQL的函数date_format(date,format);
date_format()函数来提取出日期中的“年月日”部分
date表示想要转换的日期,format表示目标格式
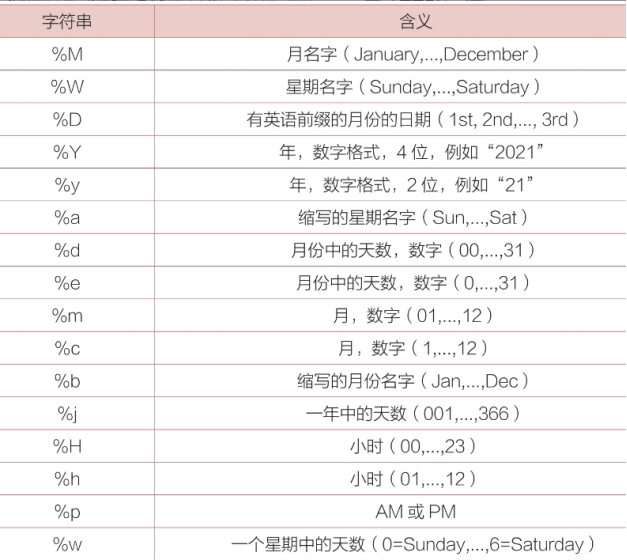
想从表中“日期”列获取星期六的日期,那么用date_format()函数可以写成如下形式,其中,format的值%w表示用于获取星期几。
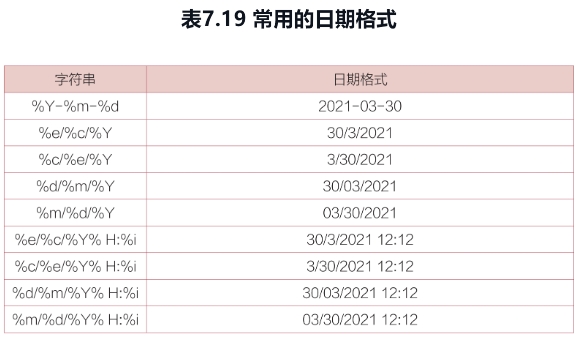
面试题:
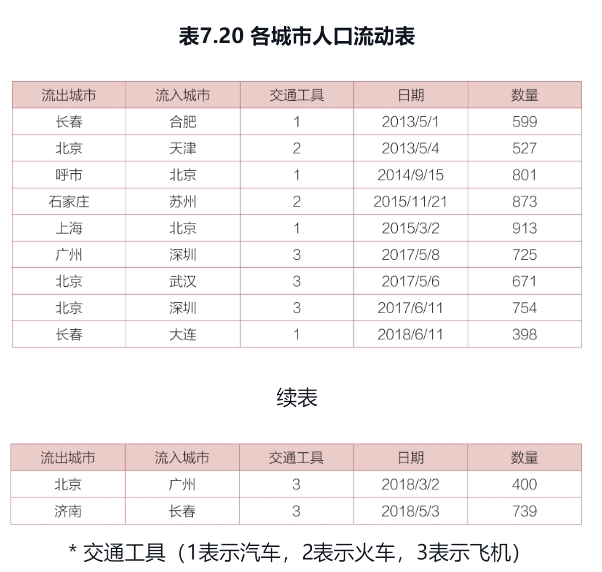
请统计2017年乘飞机在周末从北京流出的人口数。
select 流出城市,sum(数量) as 流出总人口数
from 各城市人口流动表
where 流出城市 = ‘北京’
and 交通工具 = 3
and year(日期) = “2017”
and (date_format(日期,%w) = 0 or date_format(日期,%w) = 6);
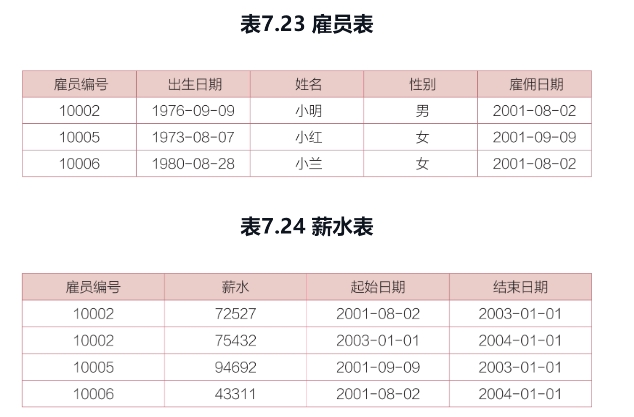
问题:查找当前所有雇员入职以来的薪水涨幅,给出雇员编号及对应的薪水涨幅,并按照薪水涨幅进行升序排列。
当前薪水是“薪水表”中的“结束日期”为“2004-01-01”对应的薪水。
入职薪水是“雇员表”中的“雇佣日期”与“薪水表”中的“起始日期”一致时对应的薪水。
with t1 as
(select 雇员编号,薪水 as 起始薪水
from 雇员表 as a
left join 薪水表 as b
on a.雇员编号= b.雇员编号 and a.雇佣日期 = b. 起始日期),
t2 as
(select 雇员编号,薪水 as 当前薪水
from 薪水表
where 结束日期= “2004-01-01”)
select 雇员编号 ,(当前薪水 – 起始薪水) as 薪水涨幅
from t1 as a
left join t2 as b
on a.雇员编号= b.雇员编号;
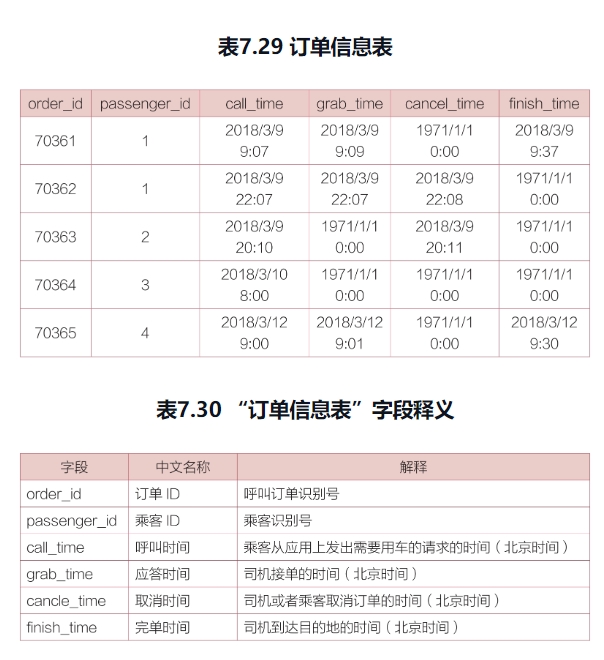
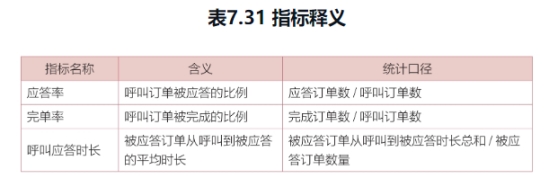
“订单信息表”里记录了巴西乘客使用打车软件的信息,包括订单ID、乘客ID、呼叫时间、应答时间、取消时间、完单时间,
(1) 表中的时间是北京时间,巴西时间比中国时间晚11个小时。
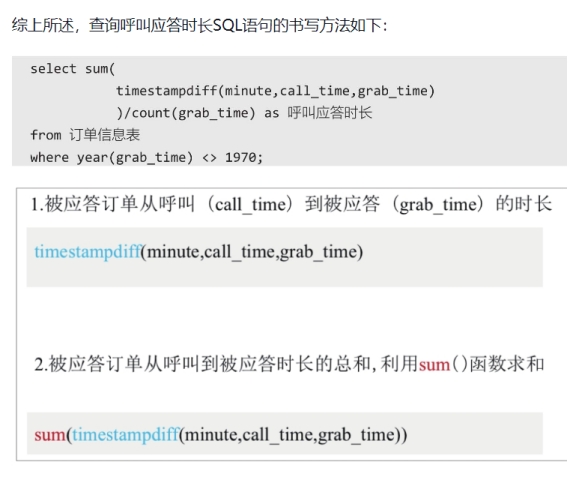
(2)“grab-time”(应答时间)列的数据值如果是“1971/1/10:00”,则表示该订单没有司机应答,属于无效订单。
(1) 订单的应答率、完单率分别是多少?
(2) 呼叫应答时长有多久?
(3) 从这一周的数据来看,呼叫量最多的是哪一个小时(当地时间)?呼叫量最少的是哪一个小时(当地时间)?
(4) 第二天继续呼叫的乘客占多大比例?
(5) 如果要对乘客进行分类,你认为需要参考哪些因素?
update 订单信息表 set call_time = cast(call_time as datetime);
update 订单信息表 set grab_time = cast(grab_time as datetime);
update 订单信息表 set cancel_time = cast(cancel_time as datetime);
update 订单信息表 set finish_time = cast(finish_time as datetime);
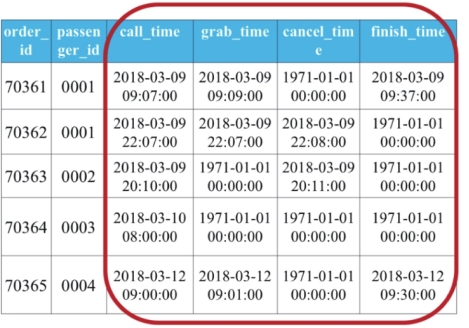
update 订单信息表 set call_time = date_sub(call_time,interval 11 hour);
update 订单信息表 set grab_time = date_sub(grab_time,interval 11 hour);
update 订单信息表 set cancel_time = date_sub(cancel_time,interval 11 hour);
update 订单信息表 set finish_time = date_sub(finish_time,interval 11 hour);
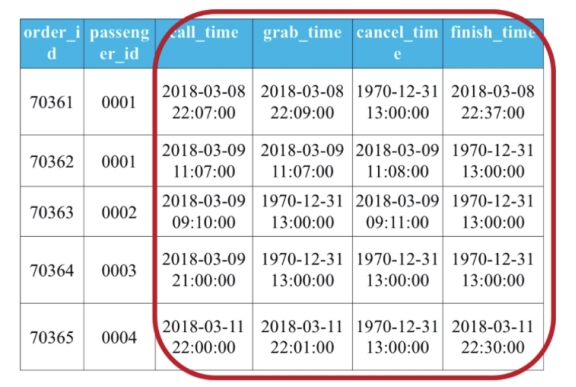
select sum(
case
when year(grab_time) <> 1970 then 1
else 0)/count(call_time) as 应答率
from 订单信息表;