

当查询涉及多个表时,需要多表连接
多表连接的类型有:内连接,左连接,右连接,全连接。
当想要生成固定行数的表单或者特定说明了要哪一个表里的全部数据,就使用左连接或者右连接
其他情况使用内连接,取两个表的公共部分
全连接的本质是返回左右表中的所有数据
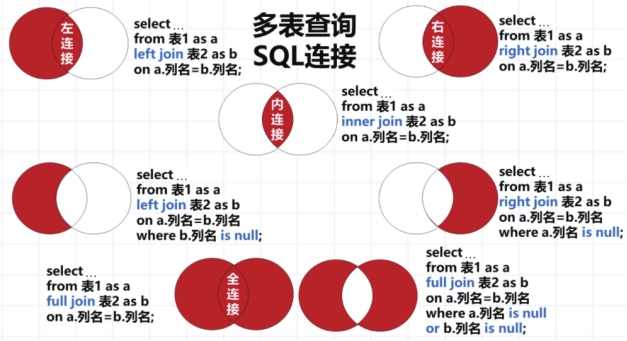
左表是在SQL语句中from 后面的表,右表位于join 中
左连接:返回左表中的所有记录,以及右表中所有匹配的记录,如果右表中没有匹配的记录,那么就返回null
右连接:返回右表中的所有记录,以及左表中所有匹配的记录,如果左表中没有匹配的记录,那么就返回null
用as关键字重命名为别名b。需要注意的是,多表查询时,当两个表有重复字段时,为了区别,需要在使用的字段前面加上表的别名,标明字段来自哪个表。因为在部分数据库中,如果不写上重名字段的来源,查询时就会报错。
面试题:
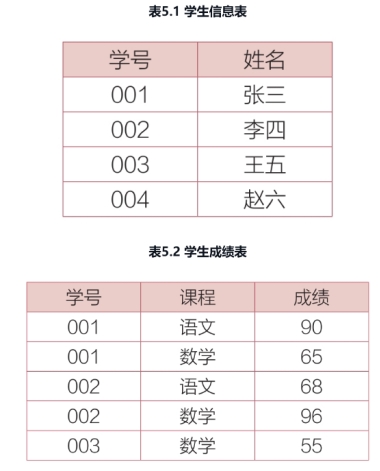
现在要查找出所有学生的学号、姓名、课程和成绩。
要求所有所有学生,那么就要保留学生信息表中的所有信息,但是学生成绩表中缺少004的成绩,所以要将学生信息表视为左表,对学生成绩表进行左连接
select a.学号,a.姓名,b.成绩
from 学生成绩表 as a
left join 学生成绩表 as b
on a.学号 = b.学号;
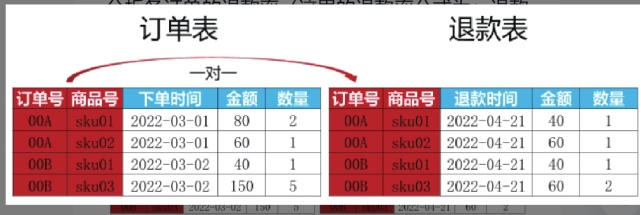
分析*各订单*的退款率(这里的退款率公式为:退款率=退款金额/订单金额)。
select 订单号, sum(b.金额)/sum(a.金额) as ‘退款率’
from 订单表 as a
left join 退款表
on a.订单号 = b .订单号
and a.商品号 = b. 商品号
group by 订单号;
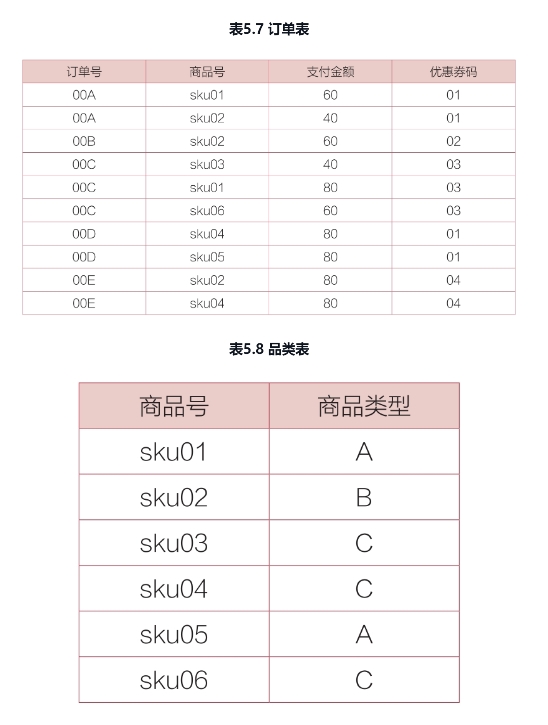
某电商公司请了某红人做推广营销,并设置专属优惠券,*券码为01,主推品类B*,我们将满足以下条件的订单作为红人订单:包含主推品类B,且使用红人专属优惠券。表5.7和表5.8所示为该公司的“订单表”和“品类表”。“订单表”记录了订单流水信息,表中的“优惠券码”字段值为字符串类型。“品类表”记录了“商品号”对应的品类。*请分析该红人带来多少订单和销售额。*
select count(distinct 订单号) as “红人订单量”,
sum(支付金额) as “红人销售额”
from 订单表
where 订单表 in(
select a.订单号
from 订单表 as a
inner join 品类表 as b
on a.商品号 = b.商品号
where a.优惠券码 = ‘01’ and 商品品类 = ‘B’);
窗口函数也叫作OLAP(联机分析处理)函数,对数据库中的数据进行复杂性分析
窗口函数的语法:
<窗口函数> over (
partition by <用于分组的列名> // 表示按某列分组
order by <用于排序的列名> // 表示对分组后的结果按某列排序
)
(1) <窗口函数>的位置可以放两种函数:一种是专用窗口函数,比如用于排名的函数,比如rank()、dense_rank()、row_number();另一种是汇总函数,比如sum()、avg()、count()、max()、min()。
(2) 因为窗口函数通常是对where或者group by子句处理后的结果进行操作的,所以窗口函数原则上只能写在select子句中。
窗口函数可以解决这几类经典问题:排名问题、Top N问题、前百分之N问题、累计问题、每组内比较问题、连续问题。这些问题在工作中你会经常遇到,比如,排名问题,对用户搜索关键字按搜索次数排名、对商品按销售量排名。再如,领导想让你找出每个部门业绩排名前10的员工进行奖励,这其实就是Top N问题。再如,要分析复购用户有多少,这类问题属于前百分之N的问题。再如,公司对各月发放的工资累计求和,医院要经常统计累计患者数,这类问题就是累计问题。
常见的排名函数:rank() , dense_rank() , row_number()
rank() 函数是排名结果考虑并列排名,但是排名序号不连续。
例如,在表6.1中,成绩100、100、100是一样的,所以这三行的排名结果都是1。然后成绩98顺着序号排在第4名(在“成绩”列中,98是第4个数据),也就是在最终排名结果中排名序号是不连续的。
dense_rank() 函数排名考虑并列排名,排名序号连续
在表6.1中,成绩100、100、100是一样的,所以这三行的排名结果都是1。和rank()函数不同的是,dense_rank()函数的排名序号要保持连续,所以成绩98顺着前面的序号排在第2名。
row_number()函数不考虑并列列名,排名序号连续
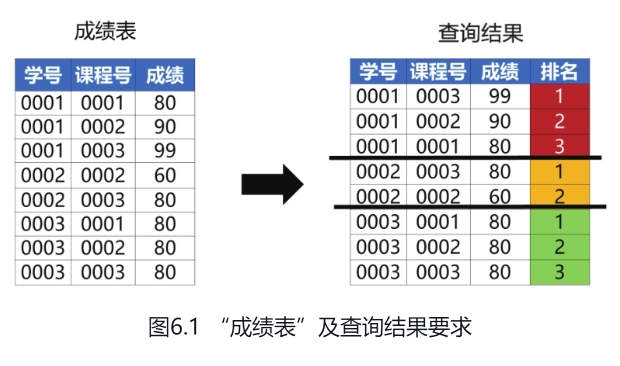
现有“成绩表”,需要我们取得每名学生不同课程的成绩排名
select * , row_number() (
partition by 学号
order by 成绩 desc
)as 排名
from 成绩表;
order by子句的功能是对分组后的结果进行排序,默认按照升序(asc)排列。
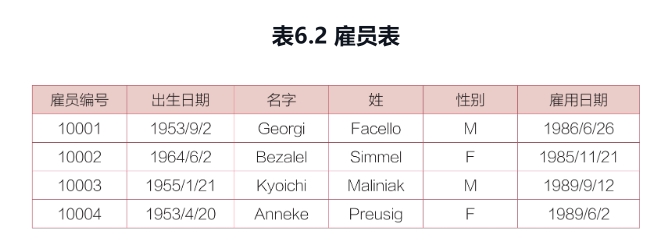
查找按名字的首字母升序排列后所在的行数为奇数行的雇员的名字。
select 名字 from (
select row_number() over (order by 名字) as 序号,名字
from 雇员表
) as a
where mod(序号,2) = 1;
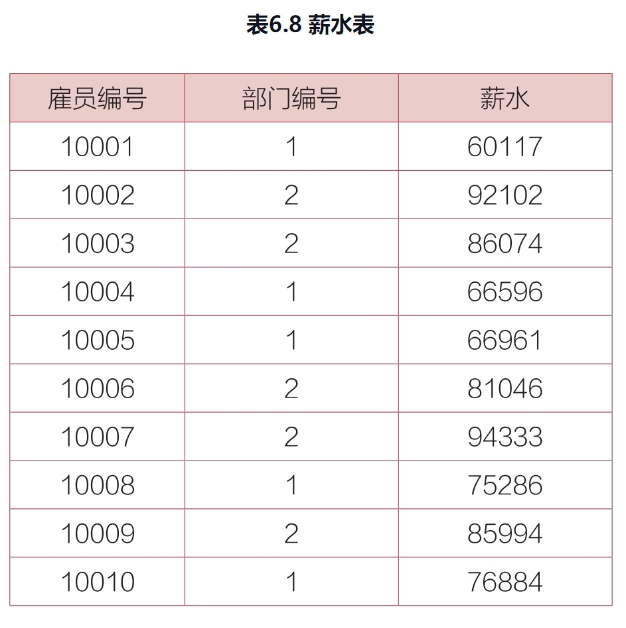
“薪水表”中记录了雇员编号、部门编号和薪水,如表6.8所示。要求查询出每个部门去除最高、最低薪水后的平均薪水。
select 部门编号,avg(薪水) as 平均薪水
from(
select *,rand() over (partition by 部门编号 order by 薪水) as min,
rank() over (partition by 部门编号 order bu 薪水 dasc) as max
from 薪水表
) as a
where a.min >1 and max > 1
group by 部门编号;
工作中会经常遇到这样的业务问题:• 如何找到每个类别下用户最喜欢的商品?• 如何找到每个类别下用户点击最多的5个商品?这类问题其实就是非常经典的Top N问题,也就是在对数据分组后,取每组里的最大值、最小值,或者每组里最大的N行(Top N)数据。 面试题:
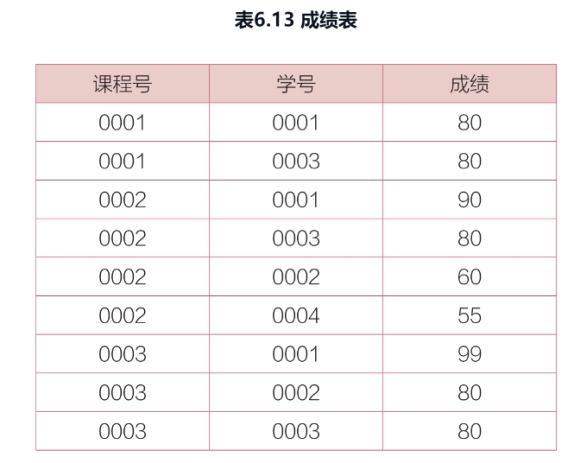
“成绩表”中记录了学生选修的课程号、学生的学号,以及对应课程的成绩,如表6.13所示。为了对学生成绩进行考核,现需要查询每门课程前三名学生的成绩。注意:如果出现同样的成绩,则视为同一个名次。
select distinct a.课程号,a.成绩
from(
select *,dense_rank() over(
partition by 课程号
order by 成绩 desc) as 排名
from 成绩表
) as a
where a.排名<=3;
遇到前百分之N问题,可以使用窗口函数percent_rank()。
• percent_rank()是专门用于计算百分位数的窗口函数。该函数内部使用的计算公式为:(rank-1)/(total_rows-1),在此公式中,rank是排名,total_rows是行数,这样就可以得到百分位数。
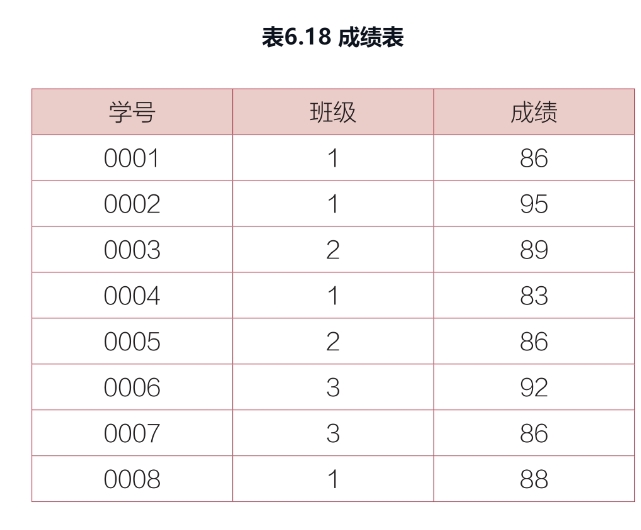
现在查询每个班级成绩排在前40%的学生信息。
select *
from(
select * ,percent_rank() over (
partition by 班级
order by 成绩 desc
)as 百分比
from 成绩表
)as a
where a.百分比 <=0.4;
其实,使用汇总函数作为窗口函数就可以实现累计分析。比如,汇总函数sum()用在窗口函数中,表示对数据进行累计求和。
所谓累计,就是类似于2*N问题,每一步的结果是基于前一步的数量的基础上,一步一步的累加上去的
移动窗口,顾名思义,“窗口”(也就是操作数据的范围)不是固定的,而是随着设定条件逐行移动的。在over后面的子句中,使用rows加“范围关键字”可以设置移动窗口,语法如下:
*窗口函数 over (*
*partition by <需要分组的列名>*
*order by <需要排序的列名>*
*rows between <范围起始行> and <范围终止行>*
*)*
其中,“范围起始行”和“范围终止行”使用特定关键字表示,常用的特定关键字如下。• n preceding:当前行的前n行。• n following:当前行的后n行。• current row:当前行。• unbounded preceding:第1行。• unbounded following:最后1行。
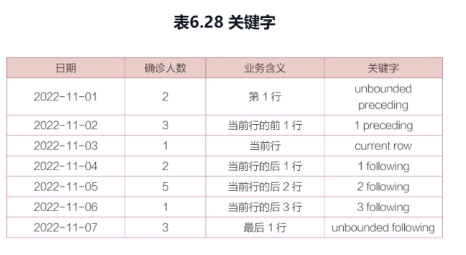

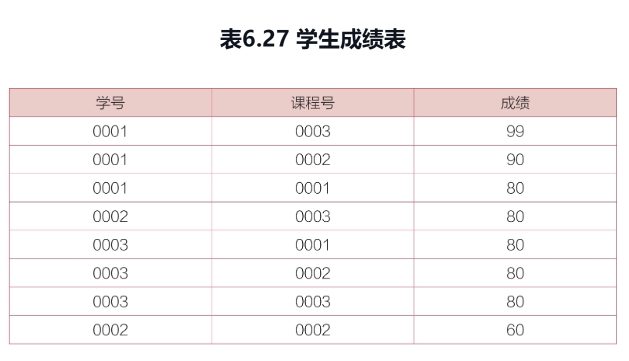
表6.27所示为“学生成绩表”,需要在按“成绩”列从大到小排列之后,*进行累计求和计算。*
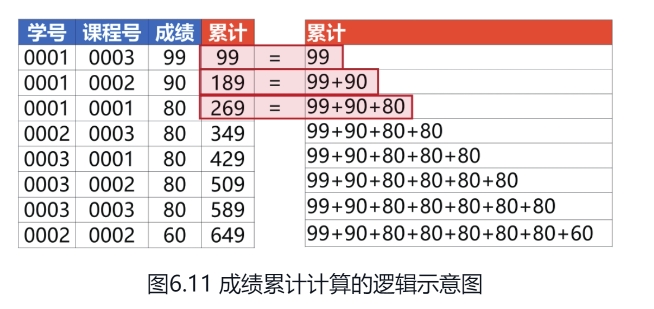
select *, sum(成绩) over(
partition by 学号
order by 成绩 desc
rows between unbounded preceding and current
)as 累计
from 学生成绩表
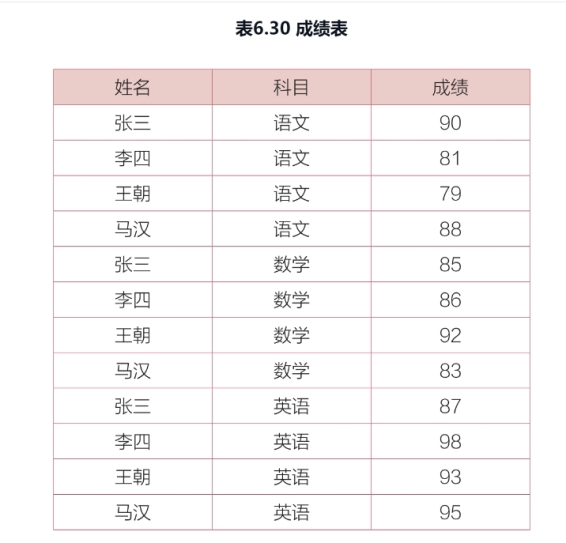
现在要查找单科成绩高于该科目平均成绩的学生名单。
select 科目,姓名
from(
select *,avg(成绩) over (
partition by 科目
) as 平均成绩
from 成绩表
)as a
where a.成绩 > a.平均成绩;
连续问题用偏移窗口函数lead()、lag()来解决。我们通过面试题来看一下如何解决连续问题。
• 向上偏移窗口函数lead():取出所在列*向上*N行的数据,作为独立的列。
• 向下偏移窗口函数lag():取出所在列*向下*N行的数据,作为独立的列。
lead(列名,N,默认值) over (partition by order by)
lag(列名,N,默认值) over (partition by order by) 两支篮球队进行了激烈的比赛,比分交替上升。比赛结束后,你有一个两队分数的明细表(名称为“分数表”),如图6.14所示。表中记录了球队、球员号码、球员姓名、得分分数及得分时间。现在球队要对比赛中表现突出的球员进行奖励。
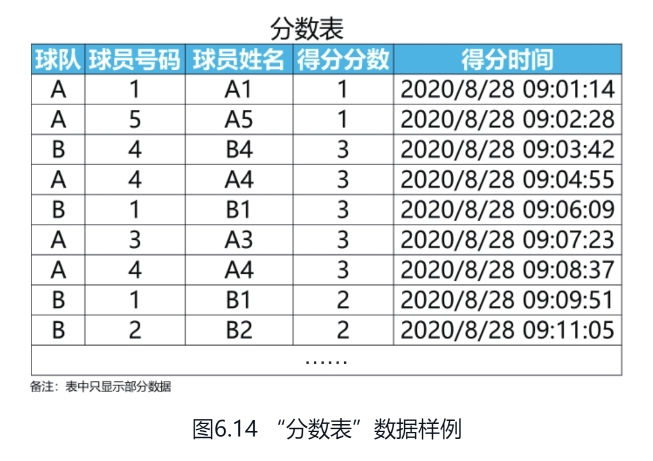
问题:请你写一个SQL语句,统计出连续3次为球队得分的球员名单。
select distinct 球员姓名
from(
select 球员姓名,
lead(球员姓名,1) over (partition by 球队 order by 得分时间) as 排名1
lead(球员姓名,2) over (partition by 球队 order by 得分时间) as 排名2
from 分数表
) as a
where a.球员姓名= a.排名1 and a.排名1 = a.排名2;